RIGHTBRAIN BLOG
How to run and test a task on Rightbrain
How to run and test a task on Rightbrain
A quick guide on how to run a task on sample data within the Rightbrain dashboard
(If you'd prefer to read this guide on notion, then click here.)
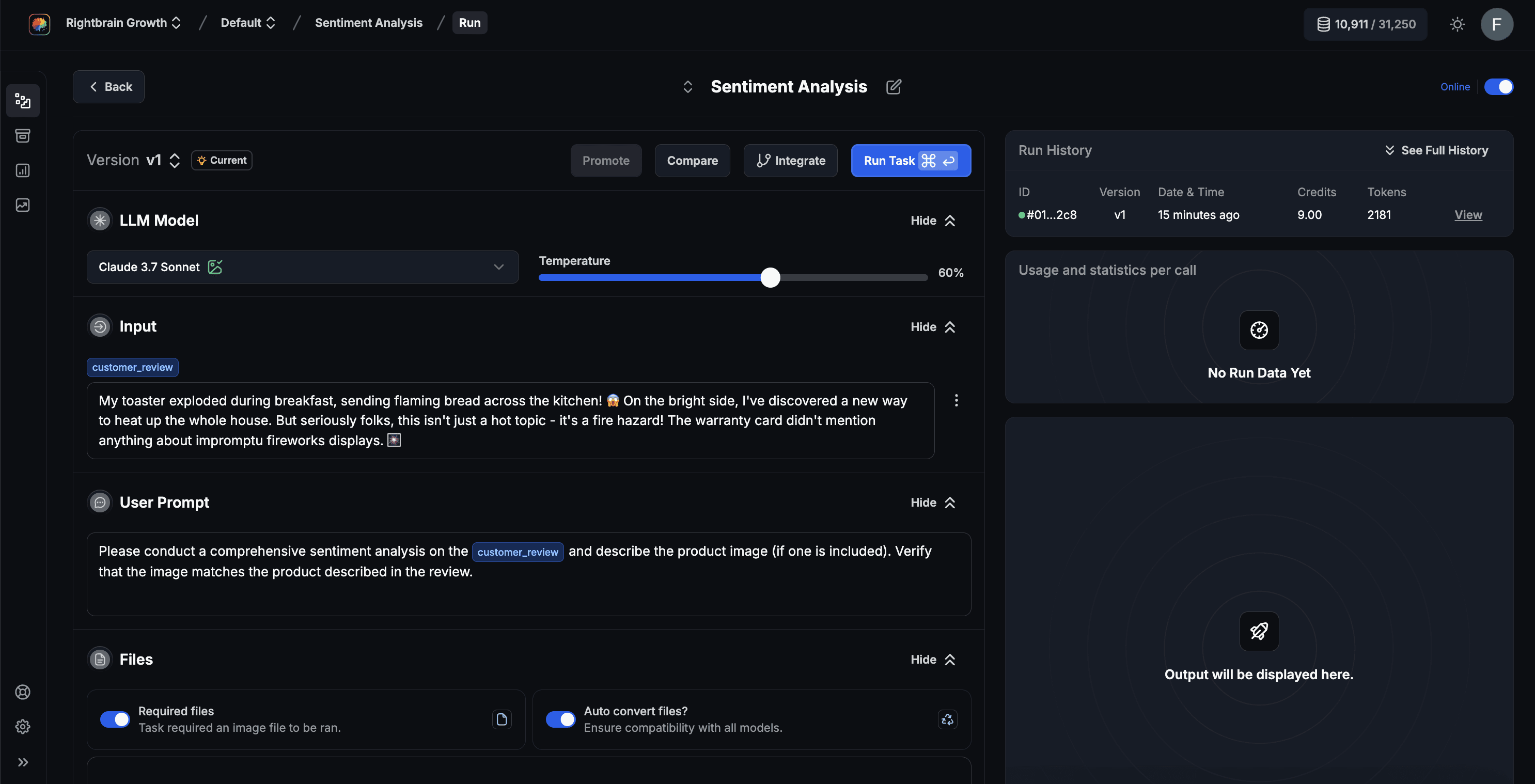
To validate an LLM’s performance, navigate to the Run Task view. You can access this directly from the Task view (where you landed once you created a task).
In the Run Task view, the left panel displays your task configuration—including the user prompt, system prompt, chosen model, and defined outputs.
Testing on input data
You can then enter or upload the input data for the task. Remember, the task is set up to run on dynamic input variables (e.g., {customer_review}). In other words, you instruct the LLM to execute the prompts on the provided input and produce outputs in the required format.
🧠 Dynamic inputs can be text, images, URLs, or a combination. Each task can have as many dynamic input variables as required. For example, you might you might have a task that compares text to images, or summarises a range of numerical and text data. You could also have a task that scrapes a URL and analyses the data returned.
For this demo, enter the following dummy {customer_review} in the input field:
"My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆"
We’re also going to add an image of a burnt toaster as evidence. If you'd like to try a version without an image, simply disable 'Required Files'.
Click Run Task (or press ⌘↩️) to execute the task. Within seconds, the model’s response appears in the right panel.
Understanding the Response
After running the task you will receive the model’s response, which you can view rendered or in raw JSON. This will be accompanied by key stats including latency, token counts and cost in credits. The keen eyed will also notice that the task run has now been added to the ‘Run History’ - a log of all your historical task runs.
Here’s an example of the raw response:
{ "task_id": "0195d1ff-1f05-437a-95ac-6de8969cb47b", "task_revision_id": "0195d1ff-1f42-f14e-8b65-641baf9dc32e", "response": { "sentiment": "negative", "image_match": true, "image_description": "The image shows a severely damaged toaster that appears to have caught fire or exploded. The toaster is blackened and charred, with melted plastic visible around its exterior. It's sitting on a black countertop with burn marks and residue surrounding it. The electrical cord is still attached, and the toaster is positioned in what looks like a kitchen setting with tiled walls in the background. The damage is extensive and consistent with the fire hazard described in the review." }, "run_data": { "submitted": { "customer_review": "My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆" }, "files": [ "be8d9e69-9f2a-4bfd-bbf4-559d6b4eb5d0.jpeg" ] }, "id": "0195d207-32bb-d03d-cfdc-f4516e9222c8", "created": "2025-03-26T10:37:15.687874Z", "input_tokens": 2051, "output_tokens": 130, "total_tokens": 2181, "input_processor_timing": 0.0001468900591135025, "llm_call_timing": 4.773190421052277, "charged_credits": "9.00" }
Key Points:
Task ID & Revision ID: Unique identifiers required when calling the task API.
Response Section: Contains the outputs in the specified format (e.g., sentiment, keywords, actions).
Run Data: Displays the input data and any files submitted.
Metadata: Includes a unique run ID, timestamp (
created), token counts (input, output, total), and processing times for troubleshooting and performance assessment.Cost: Total number of credits used to run the task.
Iterating on your task
Based on the results, you can refine your prompts, experiment with different models, adjust parameters like temperature, or modify your output structures. You can also test the task with various input data to optimise performance.
Let’s try making some changes to the user prompt and add a category output. Prior to running the task, you will notice that this will create a new revision of the task. Versioning is built-in to the Rightbrain platform to allow you to safely iterate and improve on your tasks. All revisions are available for you to access and compare later on.
The primary way in which you can iterate on tasks in Rightbrain is through Compare mode - a way to build and test different versions side-by-side.
(If you'd prefer to read this guide on notion, then click here.)
To validate an LLM’s performance, navigate to the Run Task view. You can access this directly from the Task view (where you landed once you created a task).
In the Run Task view, the left panel displays your task configuration—including the user prompt, system prompt, chosen model, and defined outputs.
Testing on input data
You can then enter or upload the input data for the task. Remember, the task is set up to run on dynamic input variables (e.g., {customer_review}). In other words, you instruct the LLM to execute the prompts on the provided input and produce outputs in the required format.
🧠 Dynamic inputs can be text, images, URLs, or a combination. Each task can have as many dynamic input variables as required. For example, you might you might have a task that compares text to images, or summarises a range of numerical and text data. You could also have a task that scrapes a URL and analyses the data returned.
For this demo, enter the following dummy {customer_review} in the input field:
"My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆"
We’re also going to add an image of a burnt toaster as evidence. If you'd like to try a version without an image, simply disable 'Required Files'.
Click Run Task (or press ⌘↩️) to execute the task. Within seconds, the model’s response appears in the right panel.
Understanding the Response
After running the task you will receive the model’s response, which you can view rendered or in raw JSON. This will be accompanied by key stats including latency, token counts and cost in credits. The keen eyed will also notice that the task run has now been added to the ‘Run History’ - a log of all your historical task runs.
Here’s an example of the raw response:
{ "task_id": "0195d1ff-1f05-437a-95ac-6de8969cb47b", "task_revision_id": "0195d1ff-1f42-f14e-8b65-641baf9dc32e", "response": { "sentiment": "negative", "image_match": true, "image_description": "The image shows a severely damaged toaster that appears to have caught fire or exploded. The toaster is blackened and charred, with melted plastic visible around its exterior. It's sitting on a black countertop with burn marks and residue surrounding it. The electrical cord is still attached, and the toaster is positioned in what looks like a kitchen setting with tiled walls in the background. The damage is extensive and consistent with the fire hazard described in the review." }, "run_data": { "submitted": { "customer_review": "My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆" }, "files": [ "be8d9e69-9f2a-4bfd-bbf4-559d6b4eb5d0.jpeg" ] }, "id": "0195d207-32bb-d03d-cfdc-f4516e9222c8", "created": "2025-03-26T10:37:15.687874Z", "input_tokens": 2051, "output_tokens": 130, "total_tokens": 2181, "input_processor_timing": 0.0001468900591135025, "llm_call_timing": 4.773190421052277, "charged_credits": "9.00" }
Key Points:
Task ID & Revision ID: Unique identifiers required when calling the task API.
Response Section: Contains the outputs in the specified format (e.g., sentiment, keywords, actions).
Run Data: Displays the input data and any files submitted.
Metadata: Includes a unique run ID, timestamp (
created), token counts (input, output, total), and processing times for troubleshooting and performance assessment.Cost: Total number of credits used to run the task.
Iterating on your task
Based on the results, you can refine your prompts, experiment with different models, adjust parameters like temperature, or modify your output structures. You can also test the task with various input data to optimise performance.
Let’s try making some changes to the user prompt and add a category output. Prior to running the task, you will notice that this will create a new revision of the task. Versioning is built-in to the Rightbrain platform to allow you to safely iterate and improve on your tasks. All revisions are available for you to access and compare later on.
The primary way in which you can iterate on tasks in Rightbrain is through Compare mode - a way to build and test different versions side-by-side.
(If you'd prefer to read this guide on notion, then click here.)
To validate an LLM’s performance, navigate to the Run Task view. You can access this directly from the Task view (where you landed once you created a task).
In the Run Task view, the left panel displays your task configuration—including the user prompt, system prompt, chosen model, and defined outputs.
Testing on input data
You can then enter or upload the input data for the task. Remember, the task is set up to run on dynamic input variables (e.g., {customer_review}). In other words, you instruct the LLM to execute the prompts on the provided input and produce outputs in the required format.
🧠 Dynamic inputs can be text, images, URLs, or a combination. Each task can have as many dynamic input variables as required. For example, you might you might have a task that compares text to images, or summarises a range of numerical and text data. You could also have a task that scrapes a URL and analyses the data returned.
For this demo, enter the following dummy {customer_review} in the input field:
"My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆"
We’re also going to add an image of a burnt toaster as evidence. If you'd like to try a version without an image, simply disable 'Required Files'.
Click Run Task (or press ⌘↩️) to execute the task. Within seconds, the model’s response appears in the right panel.
Understanding the Response
After running the task you will receive the model’s response, which you can view rendered or in raw JSON. This will be accompanied by key stats including latency, token counts and cost in credits. The keen eyed will also notice that the task run has now been added to the ‘Run History’ - a log of all your historical task runs.
Here’s an example of the raw response:
{ "task_id": "0195d1ff-1f05-437a-95ac-6de8969cb47b", "task_revision_id": "0195d1ff-1f42-f14e-8b65-641baf9dc32e", "response": { "sentiment": "negative", "image_match": true, "image_description": "The image shows a severely damaged toaster that appears to have caught fire or exploded. The toaster is blackened and charred, with melted plastic visible around its exterior. It's sitting on a black countertop with burn marks and residue surrounding it. The electrical cord is still attached, and the toaster is positioned in what looks like a kitchen setting with tiled walls in the background. The damage is extensive and consistent with the fire hazard described in the review." }, "run_data": { "submitted": { "customer_review": "My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆" }, "files": [ "be8d9e69-9f2a-4bfd-bbf4-559d6b4eb5d0.jpeg" ] }, "id": "0195d207-32bb-d03d-cfdc-f4516e9222c8", "created": "2025-03-26T10:37:15.687874Z", "input_tokens": 2051, "output_tokens": 130, "total_tokens": 2181, "input_processor_timing": 0.0001468900591135025, "llm_call_timing": 4.773190421052277, "charged_credits": "9.00" }
Key Points:
Task ID & Revision ID: Unique identifiers required when calling the task API.
Response Section: Contains the outputs in the specified format (e.g., sentiment, keywords, actions).
Run Data: Displays the input data and any files submitted.
Metadata: Includes a unique run ID, timestamp (
created), token counts (input, output, total), and processing times for troubleshooting and performance assessment.Cost: Total number of credits used to run the task.
Iterating on your task
Based on the results, you can refine your prompts, experiment with different models, adjust parameters like temperature, or modify your output structures. You can also test the task with various input data to optimise performance.
Let’s try making some changes to the user prompt and add a category output. Prior to running the task, you will notice that this will create a new revision of the task. Versioning is built-in to the Rightbrain platform to allow you to safely iterate and improve on your tasks. All revisions are available for you to access and compare later on.
The primary way in which you can iterate on tasks in Rightbrain is through Compare mode - a way to build and test different versions side-by-side.
(If you'd prefer to read this guide on notion, then click here.)
To validate an LLM’s performance, navigate to the Run Task view. You can access this directly from the Task view (where you landed once you created a task).
In the Run Task view, the left panel displays your task configuration—including the user prompt, system prompt, chosen model, and defined outputs.
Testing on input data
You can then enter or upload the input data for the task. Remember, the task is set up to run on dynamic input variables (e.g., {customer_review}). In other words, you instruct the LLM to execute the prompts on the provided input and produce outputs in the required format.
🧠 Dynamic inputs can be text, images, URLs, or a combination. Each task can have as many dynamic input variables as required. For example, you might you might have a task that compares text to images, or summarises a range of numerical and text data. You could also have a task that scrapes a URL and analyses the data returned.
For this demo, enter the following dummy {customer_review} in the input field:
"My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆"
We’re also going to add an image of a burnt toaster as evidence. If you'd like to try a version without an image, simply disable 'Required Files'.
Click Run Task (or press ⌘↩️) to execute the task. Within seconds, the model’s response appears in the right panel.
Understanding the Response
After running the task you will receive the model’s response, which you can view rendered or in raw JSON. This will be accompanied by key stats including latency, token counts and cost in credits. The keen eyed will also notice that the task run has now been added to the ‘Run History’ - a log of all your historical task runs.
Here’s an example of the raw response:
{ "task_id": "0195d1ff-1f05-437a-95ac-6de8969cb47b", "task_revision_id": "0195d1ff-1f42-f14e-8b65-641baf9dc32e", "response": { "sentiment": "negative", "image_match": true, "image_description": "The image shows a severely damaged toaster that appears to have caught fire or exploded. The toaster is blackened and charred, with melted plastic visible around its exterior. It's sitting on a black countertop with burn marks and residue surrounding it. The electrical cord is still attached, and the toaster is positioned in what looks like a kitchen setting with tiled walls in the background. The damage is extensive and consistent with the fire hazard described in the review." }, "run_data": { "submitted": { "customer_review": "My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆" }, "files": [ "be8d9e69-9f2a-4bfd-bbf4-559d6b4eb5d0.jpeg" ] }, "id": "0195d207-32bb-d03d-cfdc-f4516e9222c8", "created": "2025-03-26T10:37:15.687874Z", "input_tokens": 2051, "output_tokens": 130, "total_tokens": 2181, "input_processor_timing": 0.0001468900591135025, "llm_call_timing": 4.773190421052277, "charged_credits": "9.00" }
Key Points:
Task ID & Revision ID: Unique identifiers required when calling the task API.
Response Section: Contains the outputs in the specified format (e.g., sentiment, keywords, actions).
Run Data: Displays the input data and any files submitted.
Metadata: Includes a unique run ID, timestamp (
created), token counts (input, output, total), and processing times for troubleshooting and performance assessment.Cost: Total number of credits used to run the task.
Iterating on your task
Based on the results, you can refine your prompts, experiment with different models, adjust parameters like temperature, or modify your output structures. You can also test the task with various input data to optimise performance.
Let’s try making some changes to the user prompt and add a category output. Prior to running the task, you will notice that this will create a new revision of the task. Versioning is built-in to the Rightbrain platform to allow you to safely iterate and improve on your tasks. All revisions are available for you to access and compare later on.
The primary way in which you can iterate on tasks in Rightbrain is through Compare mode - a way to build and test different versions side-by-side.
(If you'd prefer to read this guide on notion, then click here.)
To validate an LLM’s performance, navigate to the Run Task view. You can access this directly from the Task view (where you landed once you created a task).
In the Run Task view, the left panel displays your task configuration—including the user prompt, system prompt, chosen model, and defined outputs.
Testing on input data
You can then enter or upload the input data for the task. Remember, the task is set up to run on dynamic input variables (e.g., {customer_review}). In other words, you instruct the LLM to execute the prompts on the provided input and produce outputs in the required format.
🧠 Dynamic inputs can be text, images, URLs, or a combination. Each task can have as many dynamic input variables as required. For example, you might you might have a task that compares text to images, or summarises a range of numerical and text data. You could also have a task that scrapes a URL and analyses the data returned.
For this demo, enter the following dummy {customer_review} in the input field:
"My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆"
We’re also going to add an image of a burnt toaster as evidence. If you'd like to try a version without an image, simply disable 'Required Files'.
Click Run Task (or press ⌘↩️) to execute the task. Within seconds, the model’s response appears in the right panel.
Understanding the Response
After running the task you will receive the model’s response, which you can view rendered or in raw JSON. This will be accompanied by key stats including latency, token counts and cost in credits. The keen eyed will also notice that the task run has now been added to the ‘Run History’ - a log of all your historical task runs.
Here’s an example of the raw response:
{ "task_id": "0195d1ff-1f05-437a-95ac-6de8969cb47b", "task_revision_id": "0195d1ff-1f42-f14e-8b65-641baf9dc32e", "response": { "sentiment": "negative", "image_match": true, "image_description": "The image shows a severely damaged toaster that appears to have caught fire or exploded. The toaster is blackened and charred, with melted plastic visible around its exterior. It's sitting on a black countertop with burn marks and residue surrounding it. The electrical cord is still attached, and the toaster is positioned in what looks like a kitchen setting with tiled walls in the background. The damage is extensive and consistent with the fire hazard described in the review." }, "run_data": { "submitted": { "customer_review": "My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆" }, "files": [ "be8d9e69-9f2a-4bfd-bbf4-559d6b4eb5d0.jpeg" ] }, "id": "0195d207-32bb-d03d-cfdc-f4516e9222c8", "created": "2025-03-26T10:37:15.687874Z", "input_tokens": 2051, "output_tokens": 130, "total_tokens": 2181, "input_processor_timing": 0.0001468900591135025, "llm_call_timing": 4.773190421052277, "charged_credits": "9.00" }
Key Points:
Task ID & Revision ID: Unique identifiers required when calling the task API.
Response Section: Contains the outputs in the specified format (e.g., sentiment, keywords, actions).
Run Data: Displays the input data and any files submitted.
Metadata: Includes a unique run ID, timestamp (
created), token counts (input, output, total), and processing times for troubleshooting and performance assessment.Cost: Total number of credits used to run the task.
Iterating on your task
Based on the results, you can refine your prompts, experiment with different models, adjust parameters like temperature, or modify your output structures. You can also test the task with various input data to optimise performance.
Let’s try making some changes to the user prompt and add a category output. Prior to running the task, you will notice that this will create a new revision of the task. Versioning is built-in to the Rightbrain platform to allow you to safely iterate and improve on your tasks. All revisions are available for you to access and compare later on.
The primary way in which you can iterate on tasks in Rightbrain is through Compare mode - a way to build and test different versions side-by-side.
(If you'd prefer to read this guide on notion, then click here.)
To validate an LLM’s performance, navigate to the Run Task view. You can access this directly from the Task view (where you landed once you created a task).
In the Run Task view, the left panel displays your task configuration—including the user prompt, system prompt, chosen model, and defined outputs.
Testing on input data
You can then enter or upload the input data for the task. Remember, the task is set up to run on dynamic input variables (e.g., {customer_review}). In other words, you instruct the LLM to execute the prompts on the provided input and produce outputs in the required format.
🧠 Dynamic inputs can be text, images, URLs, or a combination. Each task can have as many dynamic input variables as required. For example, you might you might have a task that compares text to images, or summarises a range of numerical and text data. You could also have a task that scrapes a URL and analyses the data returned.
For this demo, enter the following dummy {customer_review} in the input field:
"My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆"
We’re also going to add an image of a burnt toaster as evidence. If you'd like to try a version without an image, simply disable 'Required Files'.
Click Run Task (or press ⌘↩️) to execute the task. Within seconds, the model’s response appears in the right panel.
Understanding the Response
After running the task you will receive the model’s response, which you can view rendered or in raw JSON. This will be accompanied by key stats including latency, token counts and cost in credits. The keen eyed will also notice that the task run has now been added to the ‘Run History’ - a log of all your historical task runs.
Here’s an example of the raw response:
{ "task_id": "0195d1ff-1f05-437a-95ac-6de8969cb47b", "task_revision_id": "0195d1ff-1f42-f14e-8b65-641baf9dc32e", "response": { "sentiment": "negative", "image_match": true, "image_description": "The image shows a severely damaged toaster that appears to have caught fire or exploded. The toaster is blackened and charred, with melted plastic visible around its exterior. It's sitting on a black countertop with burn marks and residue surrounding it. The electrical cord is still attached, and the toaster is positioned in what looks like a kitchen setting with tiled walls in the background. The damage is extensive and consistent with the fire hazard described in the review." }, "run_data": { "submitted": { "customer_review": "My toaster exploded during breakfast, sending flaming bread across the kitchen! 😱 On the bright side, I've discovered a new way to heat up the whole house. But seriously folks, this isn't just a hot topic - it's a fire hazard! The warranty card didn't mention anything about impromptu fireworks displays. 🎆" }, "files": [ "be8d9e69-9f2a-4bfd-bbf4-559d6b4eb5d0.jpeg" ] }, "id": "0195d207-32bb-d03d-cfdc-f4516e9222c8", "created": "2025-03-26T10:37:15.687874Z", "input_tokens": 2051, "output_tokens": 130, "total_tokens": 2181, "input_processor_timing": 0.0001468900591135025, "llm_call_timing": 4.773190421052277, "charged_credits": "9.00" }
Key Points:
Task ID & Revision ID: Unique identifiers required when calling the task API.
Response Section: Contains the outputs in the specified format (e.g., sentiment, keywords, actions).
Run Data: Displays the input data and any files submitted.
Metadata: Includes a unique run ID, timestamp (
created), token counts (input, output, total), and processing times for troubleshooting and performance assessment.Cost: Total number of credits used to run the task.
Iterating on your task
Based on the results, you can refine your prompts, experiment with different models, adjust parameters like temperature, or modify your output structures. You can also test the task with various input data to optimise performance.
Let’s try making some changes to the user prompt and add a category output. Prior to running the task, you will notice that this will create a new revision of the task. Versioning is built-in to the Rightbrain platform to allow you to safely iterate and improve on your tasks. All revisions are available for you to access and compare later on.
The primary way in which you can iterate on tasks in Rightbrain is through Compare mode - a way to build and test different versions side-by-side.

RELATED CONTENT
Our latest blogs and articles


Join our developer slack
Request to join our developer slack channel
Join us on

Join our developer slack
Request to join our developer slack channel
Join us on
Join our developer slack
Request to join our developer slack channel
Join us on
Join our developer slack
Request to join our developer slack channel
Join us on
Join our developer slack
Request to join our developer slack channel
Join us on
Join our developer slack
Request to join our developer slack channel
Join us on